ML operations
by Ty Myrddin
Published on March 17, 2022
Issues with reproducibility appeared. Conda did help some. Our objective is building our own pipeline infrastructure with an eye out for reproducibility issues, enabling us to easily plug in any future model as a microservice.
MLOps was born at the intersection of DevOps, Data Engineering, and Machine Learning, and is similar to DevOps. The execution is different. For a smart and balanced approach, we wished to anticipate our learning path somewhat, so we visited data science and forums, made lists of operations and testing painpoints, and ordered those in an inductive scenario.
Our backward planning path could look something like this:
- Each new idea is a new Jupyter notebook. Keeping a common codebase will get hard.
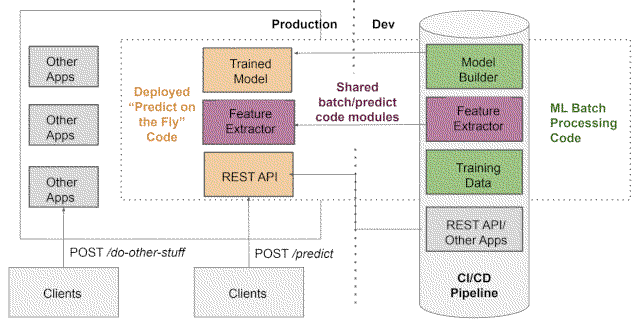
- We create a separate git repository, in which we extract a notebook of the playground codebase and make a development model notebook, then create a Python package for production from it.
- We aim at high test coverage, use type hints and pay attention to code quality. But with machine learning code, it is not always that simple. To test model code correctly, we would need to train the model. Even with a small data subset, too long for a unit test. Plus that the model trained on a small data subsample does not behave like the model trained on an entire, real dataset.
- Mypy finds issues with parts of the code that unit tests do not cover. Seeing that a function receives, or returns, something else than we expected is a simple but powerful check.
- We decide to drop some unit tests and run smoke tests. For every new pull request, we train the model in a production-like environment, on a full dataset, with the only exception that the hyperparameters are set to value that lead to getting the results fast. We monitor this pipeline for any problems, and catch them early.
- Our datasets will become larger at some point and so will our use of more powerful cloud solutions. Having environment configurations that we can trust becomes essential. Dockers enable us to have unified, sealed setups (codebase, package versions, system dependencies, configurations), no matter who and where is running it. We can now launch Jupyter from inside the container, save the hash of all the code for versioning and generate results. We store everything in git, greatly improving the reproducibility and traceability of our codebase and model changes.
- We can now move between different execution environments (Docker), tests are set up, and we can add continuous integration to make checks and reviews more efficient. We move all code checks into the Docker, including unifying versions and configurations. For local development, we use a makefile to build the image, run it, and run all the checks and tests on the code.
- Now we wish to be able to test a model for multiple datasets of different clients in different scenarios. Something we do not want to set up and run manually. We need orchestration, automated pipelines, and plugging it into the production environment easily. Docker makes it easy to move between different environments (local and cloud), and also makes it possible to connect it into the production pipeline directly as a microservice by writing a few YAMLs.
- Now how to manage all those model versions? We need to monitor the results of multiple models, trained on multiple datasets, with different parameters and metrics. And we want to be able to compare all those model versions with each other. MLFlow and Neptune are basically our main options. Neptune is more of an out-of-the-box solution enabling us to tag the experiments, save the hyperparameters, model version, metrics, and plots in a single place. And we choose less dependency and for MLFlow.
- Most likely, we wish to train a separate model for each application type with constantly growing time-series datasets. And we may wish to have a model that predicts multiple characteristics of an application. We decide to pack models into microservices for making replacing one service with another possible (using the same interface) by using FastAPI.
- How do we make sure that the model provides good insights (and not just good machine learning metrics)? Producing a static web page with plots and statistics describing the results of training does not scale that well. Automating it? Garbage in, garbage out! We will need a domain expert audit of every trained model’s results.
Now we can aim for an architecture which enables us to easily plug in any future model as a microservice.
Oh well. Last orders, please. Waiter