ML pain points
by Ty Myrddin
Published on March 12, 2022
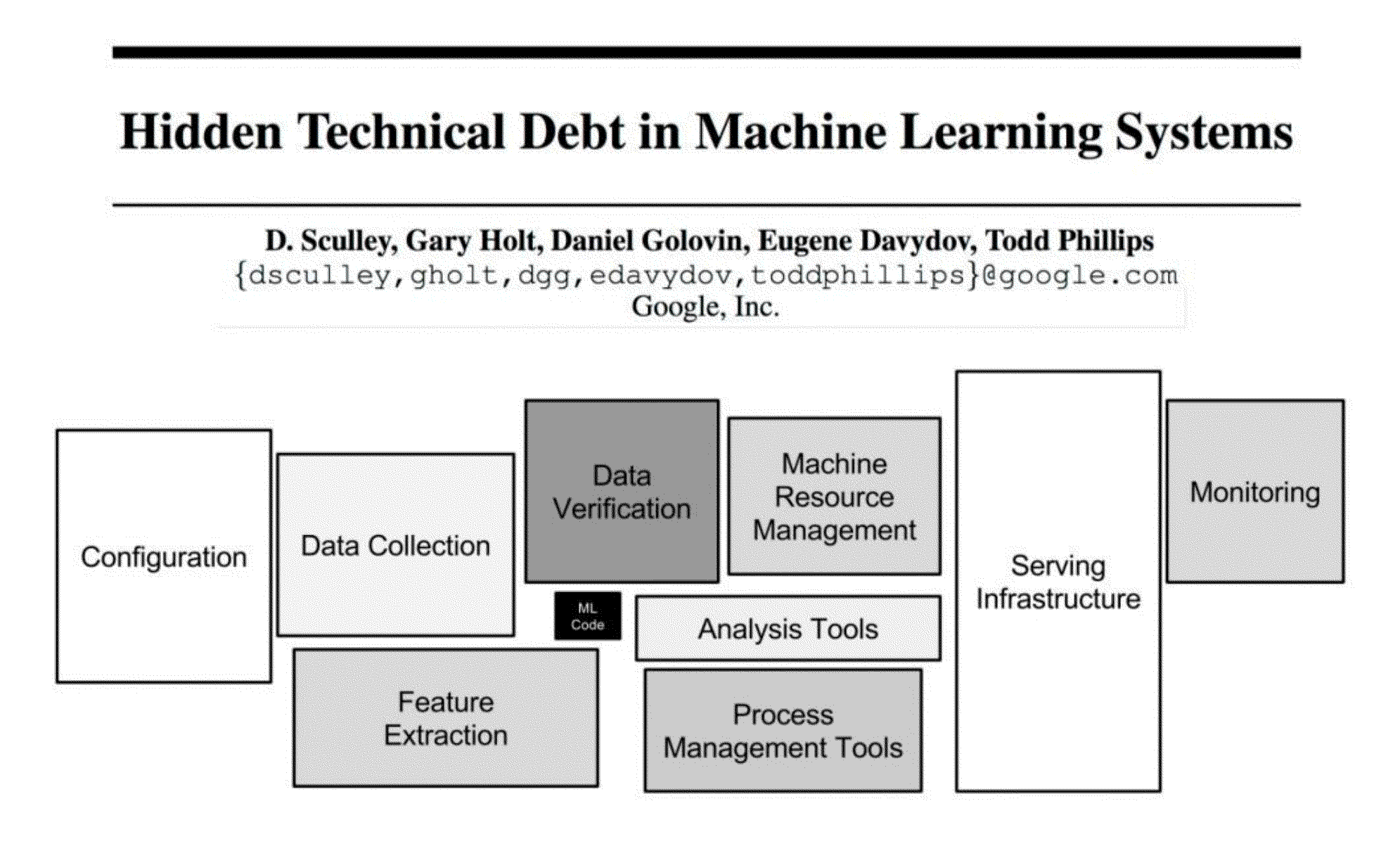
Machine Learning systems are experimental in nature and have more components that are significantly more complex to build and operate.
- In general, the more data, the better the model, and where is the data coming from? Open source and free, publicly available for a price, privately owned by a few private people? If it doesn’t already exist, where and how are we going to mine it? Would we be asked to steal private data or data that can assist in de-anonymisation practices (not an ethically acceptable proposal)?
- Many of the important and useful algorithms are open source. Not all. When the datasets are small, a model can produce biased results. Is it okay to reverse engineer an algorithm that produces better results? Alternatives are to develop, buy, or report failure and why.
- When reporting the accuracy of a model, the results a model produced are compared to actual answers. The closer they are, the higher the accuracy. Using the same set, or manufacturing a synthetic set to fit the model are not an option. Sadly, many apparently still do this.
- Besides all the efforts and tools, the ML/DL industry still struggles with the reproducibility of experiments.
- The team needed to build and deploy models in production usually includes data scientists or ML researchers, who focus on exploratory data analysis, model development, and experimentation. They might not be experienced software engineers who can build production-class services.
- Moving to the cloud.
- Even with a small data subset, testing model code can be too long for a unit test, and a model trained on a small data subsample does not behave like the model trained on an entire, real dataset. A possible solution is to drop some unit tests and run smoke tests. For every new pull request, train the model in a production-like environment, on a full dataset, with the only exception that the hyperparameters are set to value that lead to getting the results fast. Then monitor this pipeline for any problems, and catch them early, and add continuous integration to make checks and reviews more efficient.
- Creating and managing ML pipelines: An offline-trained ML model can not simply be deployed as a prediction service. This requires a multistep pipeline to automatically retrain and deploy a model. Such a pipeline adds complexity because the steps that data scientists do manually to train and validate new models need to be automated.
- ML models in production can have reduced performance not only due to suboptimal coding but also due to constantly evolving data profiles. Models can decay in more ways than conventional software systems. This can be caused by:
- A discrepancy between data is handled in the training and in the serving pipelines.
- A change in the data between training and serving.
- A feedback loop – Choosing the wrong hypothesis (i.e. objective) for optimisation, can make us collect biased data for training models. When collecting newer data points using this flawed hypothesis, it is fed back in to future versions of the model, making the model even more biased, and the snowball keeps growing.
- Scaling.
- Dealing with sensitive data at scale.
- In order to be able to refresh models in production when needed, these and summary statistics of data that built a model need to be monitored. These statistics can and will change over time. Notifications and a roll-back process are required for when values deviate from expectations.
Oh well. Last orders, please. Waiter